
こんにちは。ニフティクラウドで開発を担当している大友と言います。
本日は、2016年10月25日にリリースされましたニフティクラウド Machine Learning(現在トライアルα版として受付中)をご紹介します。
ニフティクラウド Machine Learningは、クラウド上に機械学習のモデルを構築して、UIやAPI経由でモデルの出力する予測値を得ることのできるサービスです。
※本記事は2016年11月28日時点での情報を元に執筆しています。

機械学習とは
機械学習とは、データに含まれるパターンなどをコンピュータに学習させることで、データを入力として与えた際に、何らかの有益な出力を返すプログラムを構築する仕組みです。出力を返すプログラムをモデルと呼びます。機械学習にはいくつか種類があります。以下に代表的なものを挙げます。
- 教師あり学習:正解を含むデータを学習させて、未知のデータに対する正解を予測するモデルを構築する
- 教師なし学習:データに含まれるパターンなどを抽出して出力するモデルを構築する
- 強化学習:環境と行動を定義し、環境に対して行動した結果を学習して最適な行動を出力するモデルを構築する
実際の応用例として、以下のようなものがあります。
- メールとスパムか否かのラベルをデータとして新たに受信したメールが、スパムか否かを予測するモデルを構築する(教師あり学習)
- 店舗への来客データから抽出したパターンに基づいてセグメントを分割し、施策などに活用する(教師なし学習)
- 囲碁の盤面を環境、差し手を行動として、盤面に対する差し手を学習して最適な差し手を出力するモデルを構築する(強化学習)
今回はニフティクラウド Machine Learningの機能として提供している、教師あり学習について説明していきます。
機械学習における課題
モデルを構築する際に、少なくとも下記のような課題があると考えられています。
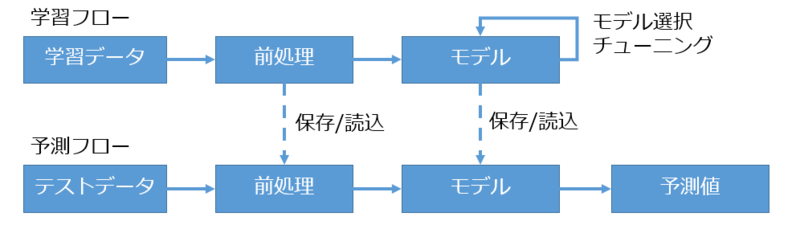
モデル構築アルゴリズムを適用するためのデータの前処理
一つめは、いわゆる前処理と呼ばれている処理です。機械学習のモデルを構築するアルゴリズムは数値を入力とするものが主になります。そこで、入力するデータを適切な形にあらかじめ処理しておく必要があります。例えば、入力の中に記号が含まれている場合などには数値化する必要があります。また、アルゴリズムによっては、入力する数値のカラムごとの大きさに影響を受けるものがあるため、数値の大きさを調整する必要があります。
機械学習のモデル選択や各モデルのハイパーパラメーターのチューニング
二つめはモデルの選択と各モデルのハイパーパラメーターのチューニングです。機械学習にいくつか種類があることは前述しましたが、その中の教師あり学習のモデルについても、いくつか種類があります。それぞれのモデルごとに特性が異なっており、あるデータでは精度の高かったモデルでも別のデータに対しては精度が低く、別のモデルの方が適している場合などがあります。このため、色々なモデルに対して精度の検証を行い、適切にモデルを選択する必要があります。また、各モデルにはハイパーパラメーターという構築を行う前にあらかじめ設定する必要のあるパラメータが存在するモデルもあり、ハイパーパラメーターの値によっても精度が変わってくるためチューニングが必要となります。
データ処理パイプラインの永続化
加えて、このようなモデルを構築する際の前処理を行い、データを入力するパイプラインは予測時にも同様に適用する必要があるため、永続化して予測時に呼び出せるようにしておくためのシステムが必要となります。
ニフティクラウド Machine Learning について
ニフティクラウド Machine Learningは、前述の様な機械学習のモデル構築における課題を解決することに注力したサービスです。主な機能として、下記を提供しています。
- 一部の前処理を行う機能の提供
- モデルの選択とハイパーパラメーターのチューニングの自動化
- 一連のパイプラインを利用した予測APIの提供
今回はこれらの機能を用いて予測モデルの構築を行ってみたいと思います。
予測モデルの構築
UCI Machine Learning Repositoryで公開されている乳がんの良悪性の予測を行うデータセットBreast Cancer Wisconsin (Diagnostic) Data Set(以下Breast Cancerデータセット)を利用して予測モデルを構築していきます。
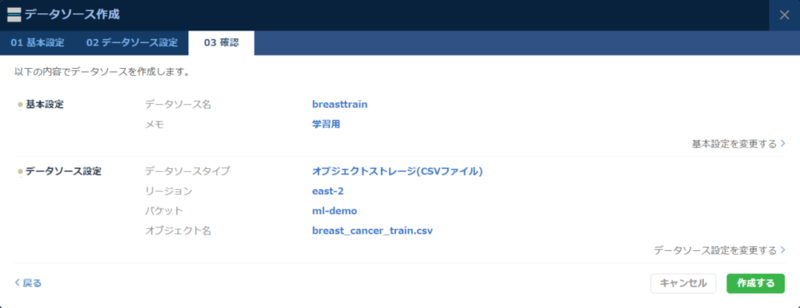
データソースの登録
ニフティクラウド Machine Learningでデータを利用するためには、まずデータソースを登録する必要があります。データソースにはMySQLかニフティクラウド オブジェクトストレージ(以下オブジェクトストレージ)にアップロードされたCSVが対応しています。今回は前述のデータセットをCSVに変換して、オブジェクトストレージから利用することにします。また、実際に利用する際は必要ありませんが、後ほど予測機能を利用するためにあらかじめテスト用のデータを分けて登録しておきます。登録には下記の様にコントロールパネルからデータソースの登録を選択し、前述のアップロードしたCSVファイルを入力します。
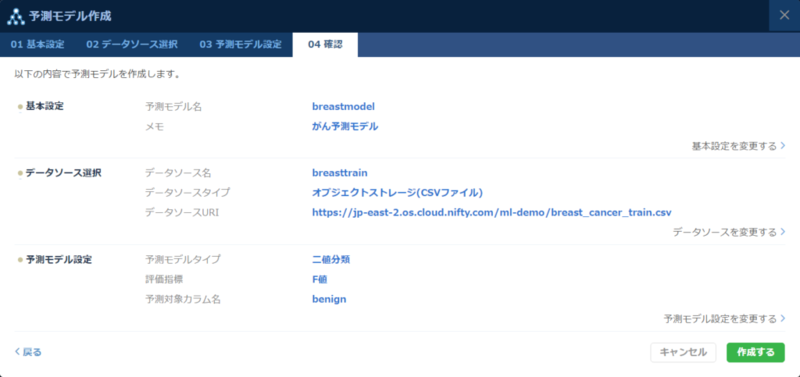
モデルの登録
続いてモデルの登録を行います。モデルの登録には先ほど登録した学習用のデータソースと予測対象となるカラムを選択します。今回予測したい属性は良悪性のため良性の場合に1となるカラムであるbenignを選択します。
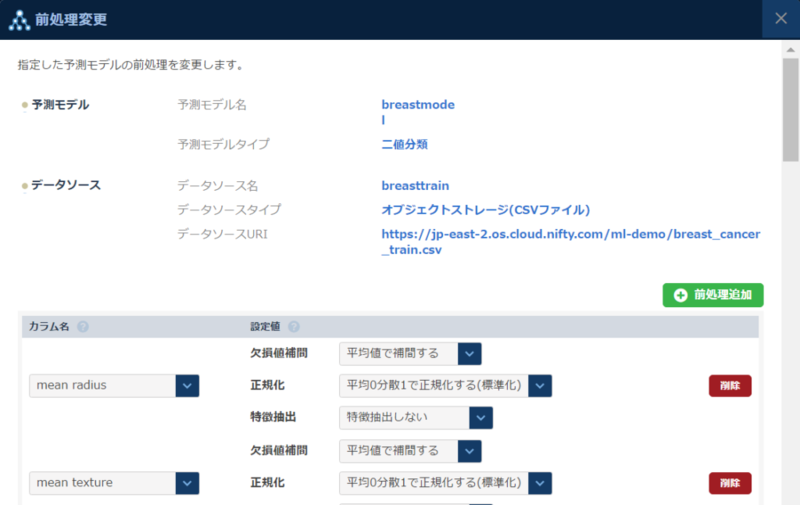
データの前処理
次に前処理の設定を行います。前処理の内容は欠損値補完、正規化、特徴抽出に対応しています。Breast Cancerデータセットは予測対象以外のカラムは実数値のため欠損値を平均値で補完し、平均0分散1で正規化します。
学習の開始
前処理の設定が終わったので学習を開始します。
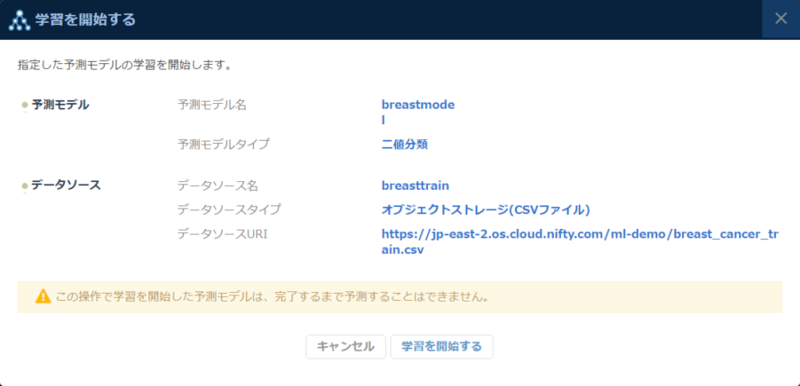
学習が完了するとモデル一覧からスコアを確認することができます。評価指標のF値は再現率(陽性のデータのうち、正しく陽性と予測できた割合)と適合率(陽性と予測したうち、正しく予測できた割合)の調和平均になります。単純に予測の正解率を指標とすると正解ラベルに偏りがある場合に多いラベルを常に予測するモデルのスコアが良くなってしまうため、機械学習では上記のような指標を用いることが多いです。
データの予測
コントロールパネルからの予測
ステータスが学習済みになると予測APIが利用可能になります。実際に利用する場合はここで正解が分からないデータに対して予測を行いますが、今回はデータソースを登録する際に用意したテスト用のデータを利用します。UIから予測を行う場合はモデル構築の際に利用する場合と同様に登録済みのデータソースに対して予測値の出力を行います。
実際の値(左側)と予測した結果(右側)とを比較してみると、正しく分類できていることがわかります。

APIを用いた予測
APIを用いて予測することも可能です。APIはAWSのSignature V4互換のためPythonの場合は下記の様にboto/botocoreを利用してリクエストすることができます。
$ cat predict.py
import os
import sys
import json
import requests
from botocore.auth import SigV4Auth
from botocore.credentials import Credentials
from botocore.awsrequest import AWSRequest
endpoint = 'https://ml.api.cloud.nifty.com/'
req = AWSRequest(
method='POST',
headers={
'x-amz-target': 'MachineLearning_20161025.Predict',
'host': 'ml.api.cloud.nifty.com',
'content-type': 'application/json',
},
data=json.dumps(json.load(open(sys.argv[1]))),
)
cred = Credentials(os.environ['ACCESS_KEY'], os.environ['SECRET_KEY'])
SigV4Auth(cred, 'machinelearning', 'east-2').add_auth(req)
print(requests.post(endpoint, headers=req.headers, data=req.body).text)
$ python predict.py payload.json | xmllint --format -
<?xml version="1.0" encoding="utf-8"?>
<PredictResponse>
<predictedLabels>
<predictedLabel>0</predictedLabel>
</predictedLabels>
<modelId>1</modelId>
</PredictResponse>
まとめ
ニフティクラウド Machine Learningを用いて、予測モデルの構築と予測を実施しました。
このようにCSVデータからカジュアルに予測モデルの構築が行えるサービスとなっておりますのでぜひご利用ください。
トライアルα版の申し込みはこちらから受付中です 。